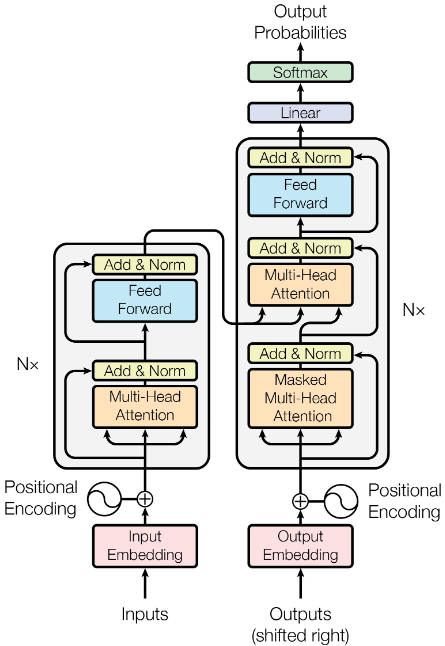
Transformer模型完全基于注意力机制,没有任何卷积层或循环神经网络。
Transformer作为编码器-解码器架构,整体架构如下图:
Transformer是由编码器和解码器组成,编码器和解码器是基于自注意力的模块叠加而成的,源序列和目标输出序列的嵌入表示将加上位置编码,再分别输入编码器和解码器中。
Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层。
第一个子层是多头自注意力汇聚
第二个子层是基于位置的前馈网络
每个子层都采用了残差链接
对于序列中任何位置的任何输入x ∈ R d x\in R^d x ∈ R d s u b l a y e r ( x ) ∈ R d sublayer(x)\in R^d s u b l a y e r ( x ) ∈ R d x + s u b l a y e r ( x ) ∈ R d x+sublayer(x)\in R^d x + s u b l a y e r ( x ) ∈ R d
再残差连接的加法计算后,紧接着应用层规范化
因此,对于输入序列的每个位置,Transformer编码器都将输出一个d d d
Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。
除了编码器中描述的两个子层,解码器还在这两个子层之间插入了第三个子层,称为编码-解码器注意力层
再解码器自注意力中,查询、键和值都来自上一个解码器层的输出
解码器中的每个位置都只能考虑该位置之前的所有位置,这种掩蔽注意力保留了自回归属性,以确保预测仅依赖已生成的输出词元
1 2 3 4 5 import math
基于位置的前馈网络对序列中的所有位置的表示进行变换时使用的是同一个多层感知机,这就是称前馈神经网络是基于位置的原因。
在下面的实现中,输入X的形状(批量大小,时间步数或序列长度,隐单元数或特征维度)将被一个两层的感知机变换成形状为(批量大小,时间步数,ffn_num_outputs)的输出张量。
1 2 3 4 5 6 7 8 9 10 #@save
下面的例子显示,改变张量的最内层维度的尺寸,会改变基于位置的前馈网络的输出尺寸。因为用同一个多层感知机对所有位置上的输入进行变换,所以当所有这些位置的输入相同时,它们的输出也是相同的。
1 2 3 ffn = PositionWiseFFN(4, 4, 8)
批量规范化是在一个小批量的样本内对数据进行重新中心化和重新缩放的调整。
层规范化与批量规范化的目标相同,但层规范化是基于特征维度进行规范化,往往使用在自然语言处理中。
现在可以使用残差连接和层规范化来实现AddNorm类,暂退法也被作为正则化方法使用。
1 2 3 4 5 6 7 8 class AddNorm(nn.Module):
残差连接要求两个输入的形状相同,以便在加法操作后输出张量的形状相同:
1 2 3 add_norm = AddNorm([3, 4], 0.5)
有了Transformer编码器的基础组件,现在可以先实现编码器中的一个层。
下面的EncoderBlock类包含两个子层:多头注意力和基于位置的前馈神经网络,这两个子层都使用了残差连接和紧随的层规范化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class EncoderBlock(nn.Module):
Transformer编码器中的任何层都不会改变其输入的形状。
1 2 3 4 5 X = torch.ones((2, 100, 24))
下面实现的Transformer编码器的代码中,堆叠了num_layers个EncoderBlock类的实例。由于这里使用的是值范围在− 1 1 -1~1 − 1 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class TransformerEncoder(d2l.Encoder):
下面我们指定超参数来创建一个两层的Transformer编码器。Transformer编码器输出的形状是(批量大小,时间步数,num_hiddens)
1 2 3 4 encoder = TransformerEncoder(
在DecoderBlock类中,实现的每个层包含3个子层:解码器自注意力,编码器-解码器注意力和基于位置的前馈网络。
这些子层也都被残差连接和紧随的层规范化围绕。
正如前面所说,在掩蔽多头解码器自注意力层中,查询、键和值都来自上一个解码器的输出。
关于序列到序列模型,在训练阶段,其输出序列的所有位置的词元都是已知的:然而在预测阶段,其输出序列的词元是逐个生成的。因此在解码器的任何时间步中,只有生成的词元才能用于解码器的自注意力计算中。
为了在解码器中保留自回归的属性,其掩蔽自注意力设定了参数dec_valid_lens,以便任何查询都只会与解码器中所有已经生成词元的位置进行注意力计算。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class DecoderBlock(nn.Module):
为了便于在编码器-解码器注意力中进行缩放点积运算和在残差连接中进行加法计算,编码器和解码器的特征维度都是num_hiddens。
1 2 3 4 5 decoder_blk = DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0)
现在我们构建Transformer解码器,最后通过一个全连接层计算所有vocab_size个可能的输出词元的预测值。解码器自注意力权重和编码器-解码器注意力权重都被存储下来,以便日后可视化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class TransformerDecoder(d2l.AttentionDecoder):
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32,32
norm_shape = [32]
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = TransformerEncoder(len(src_vocab), key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout)
decoder = TransformerDecoder(len(tgt_vocab), key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout)
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
net = EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)```